- Get link
- X
- Other Apps

This post is actually part 1 of 2 of a classification blog post. In the next blog post we will take our scraped images and use them to classify objects!
All the code can be found here if you want to get right into it.
About Image Scrapers
An image scraper is basically just a program that can download certain images from a website automatically, and is part of a "web scraper" program.
To make an image scraper, there's essentially 5 steps:
- Get all your prerequisites set up
- Open a website using a web testing library
- Loop through the website in a way that can find all the images in full size
- Store those URLs
- Download the images at the URLs locally!
Not too bad, right?
It can be pretty simple to make a simple image scraper. The hard part, depending on the website, is step 3. For example, Google images only shows you image thumbnails unless you click on them, which aren't full size. Some websites take a while to load as well.
Prerequisites
For this we will be using the Selenium and Requests libraries, so you will need to get those:
pip install selenium
pip install requests
pip install shutil
Other notable webscraping libraries include Beautiful Soup, Scrapy, and LXML. I used these on my way to learn about image scraping, and I encourage you to look at them as well.
Establishing a Connection
First, we need to figure out how we're going to get our page. If you want to just grab the images off of a specific website, you can just type in the url. Since our image scraper allows for scraping of many different queries, we have do make the url dynamically.
# Build the Google Query.
search_url = "https://www.google.com/search?safe=off&site=&tbm=isch&source=hp&q={q}&oq={q}&gs_l=img"
# load the page
wd.get(search_url.format(q=query))
wd is short for webdriver.Chrome(), part of selenium. We are making a GET request, where a new Chrome window pops up and it will navigate to the google image link automatically. Note, edge will will using webdriver.Chrome as well since it uses Chromium. If you're using mac and only have safari, you'll need webdriver.Safari().
Next, we need to find the urls to all the images. We first find the images of all the thumbnails by filtering through the CSS selector img.Q4LuWd . What does this mean? This mean that it's a thumbnail. I found this by using inspect element on the images (CTRL + Shift + I)
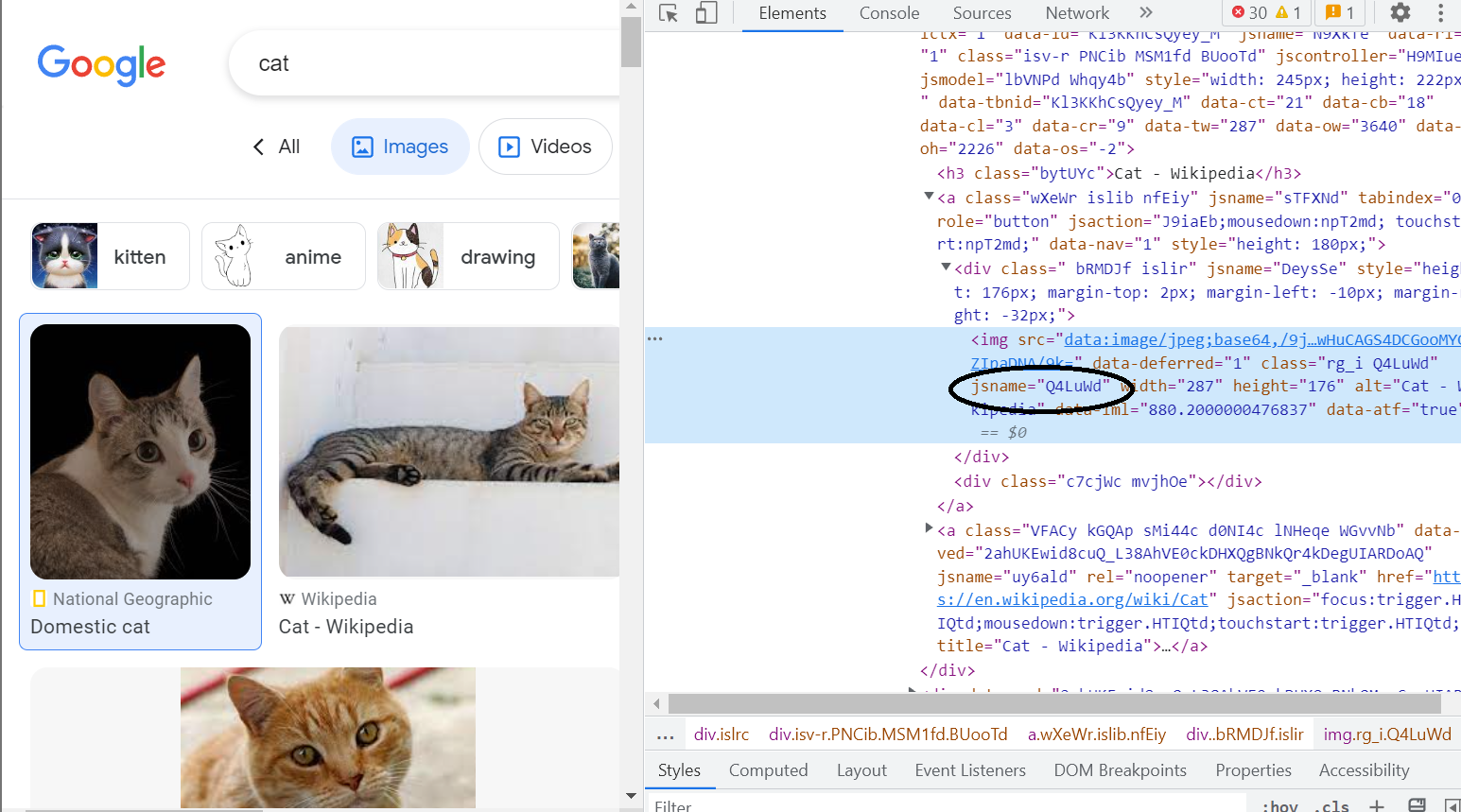
How do we identify this using selenium?
Easy! just use wd.find_elements.
In this case you can just thumbnail_results = wd.find_elements(By.CSS_SELECTOR, "img.Q4LuWd")
Looping Through and Clicking
Next on our list of importance is clicking through all of the thumbnails and trying to click to find the "full size version" of the image.
This is what it will look like when going through images. Pretty cool

Downloading images
Now you have to download the images from the url you found. You just loop through each url you retrieved and attempt to download it.
I decided to do this using the requests library, which is useful.
First, we access the URL using requests.get. We make sure the status code is correct (HTTP status code 200 means OK, everything is working correctly.)
Now we just use simple python file writing!
| try: | |
| r = requests.get(url, stream=True) | |
| if r.status_code == 200: | |
| image_number = i + quantity * index | |
| with open(folder_path + str(image_number) + '.jpg', 'wb') as f: | |
| r.raw.decode_content = True | |
| shutil.copyfileobj(r.raw, f) | |
| print("SUCCESS- Got image" + str(image_number) + " - saved to " + folder_path + str(image_number) + '.jpg') | |
| else: | |
| print("ERROR - Could not download {url} - {r.status_code}") | |
| except Exception as e: | |
| print(f"ERROR - Could not download {url} - {e}") |
Putting it all together
At this point, we're all done! I added a driver function that calls the functions of finding URLs and downloads each of these urls.
I also added a main.py where you can easily change the amount of images you want, what your search terms are, etc.
def search_and_download
| # Create a folder name. | |
| target_folder = os.path.join(target_path, "_".join(title_term.lower().split(" "))) | |
| # Open Chrome | |
| with webdriver.Chrome() as wd: | |
| # Search for images URLs. | |
| res = fetch_image_urls( | |
| search_term, | |
| number_images, | |
| wd=wd, | |
| sleep_between_interactions=SLEEP_BETWEEN_INTERACTIONS, | |
| ) | |
| # Download the images. | |
| if res is not None: | |
| for i, elem in enumerate(res): | |
| download_image(target_folder, elem, i, number_images, index) | |
| else: | |
| print(f"Failed to return links for term: {search_term}") | |
Conclusion
In this post, we learned how to
great
ReplyDeleteBuilding a Google image scraper is an interesting way to understand how large-scale image datasets are collected for machine learning and computer vision applications. This article explains the scraping workflow clearly and highlights the importance of automation in image-based AI research and development. Readers interested in practical visual AI implementations can also explore Image Classification Projects for innovative computer vision and image analysis ideas.
ReplyDeleteImage collection and preprocessing play a major role in improving the accuracy of classification and recognition models. As computer vision continues to evolve, techniques involving image scraping, labeling, and dataset management are becoming increasingly valuable for AI developers and researchers. Those exploring advanced visual computing concepts may also find image-classification-projects-for-final-year useful for discovering modern deep learning and pattern recognition applications.
ReplyDelete